Use FSTree only for writecache #1367
No reviewers
TrueCloudLab/storage-core-developers
Labels
No labels
P0
P1
P2
P3
badger
frostfs-adm
frostfs-cli
frostfs-ir
frostfs-lens
frostfs-node
good first issue
triage
Infrastructure
blocked
bug
config
discussion
documentation
duplicate
enhancement
go
help wanted
internal
invalid
kludge
observability
perfomance
question
refactoring
wontfix
No milestone
No project
No assignees
3 participants
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference: TrueCloudLab/frostfs-node#1367
Loading…
Add table
Add a link
Reference in a new issue
No description provided.
Delete branch "dstepanov-yadro/frostfs-node:feat/wc_fstree"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
What has changed:
flush and drop bbolt dbstep on init.small_object_sizeandmax_object_size.Hardware test results: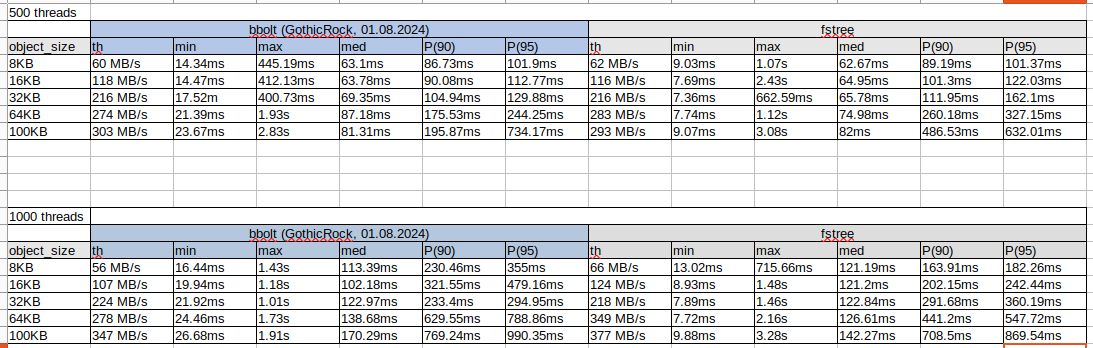
Test scenario: 5 min put, 100 containers, REP 2
10652370c2to595b8df21a595b8df21ato9258977d519258977d51to88ed60c76aWIP: Use FSTree only for writecacheto Use FSTree only for writecache88ed60c76ato87c99bab9e87c99bab9eto6a5f0c9d50@ -29,3 +31,2 @@func NewSimpleCounter() *SimpleCounter {return &SimpleCounter{}func NewSimpleCounter(assert bool) *SimpleCounter {The argument is unused.
What is the goal of having this assert? Just panic unconditionally.
Fixed
@ -225,0 +228,4 @@}type IterateInfoHandler func(ObjectInfo) errorfunc (t *FSTree) IterateInfo(ctx context.Context, handler IterateInfoHandler) error {What do we add this method for?
It seems we achieve nothing: we are limiting the amount of memory we consume by some criteria, it doesn't matter when we read object.
This implementation is stricter: writecache doesn't read object before limiter allows it.
Using of
ftree.Iterateis also possible, but the amount and complexity of the new code are small, so I chose a more strict implementation.Also it is now more than one flush worker for fstree, so using
fstree.Iteratefrom many goroutines requires some kind of synchronization to not to read the same objects.Hardly disagree, we have a whole new method to support and this is not a single point of adding small complexity in this PR.
I think the strictness doesn't matter here: the object is small and we do not perfectly control the amount of memory anyway, consider multiple slices for decompressed data and allocations during unmarshaling.
If it will be more than on flush worker that uses
fstree.Iteratethen it is possible that the same file will be readed more than once and more than once flushed to blobstore (this action requires additional memory and CPU).If multiple flush workers iterate over the same directory that is some really bad design, unless they distribute work somehow, and thus not have the problem you described.
@ -128,0 +124,4 @@w.fileGuard.Lock(p)defer w.fileGuard.Unlock(p)stat, err := os.Stat(p)Honestly, I do not like the idea of using a separate syscall just to be able to track size.
Precise estimation is obviously a new feature with non-zero cost, do we need it?
Bbolt + fstreeimplementation estimates writecache size asdbCount * small_object_size + fstreeCount * max_object_size. Such estimate is not very accurate.If the same estimate were applied for the current implementation, then the cache size limit would depend only on the objects count, and not on the actual size of the data.
In the writecache flush thread you actually read the file before removing it, so you know the size exactly.
Do we need to extend fstree?
Without fstree extend (adding filelocker) it is required to move filelocker to writecache and to add
fstree.Existscheck onwritecache.Putto handle save the same object twice.fstree.Existsonwritecache.Putaddsos.Statcall on direct client request.So I prefer to have extra syscall for background flushing but not for Put request handler.
Also now writecache passes size to
fstree.Deleteto not to callos.Stat@ -51,6 +61,10 @@ func (w *linuxWriter) writeData(p string, data []byte) error {}func (w *linuxWriter) writeFile(p string, data []byte) error {if w.fileCounterEnabled {We didn't have this before, was it a bug?
No, as we don't have
unix.Statcall.Oh, sorry. I missed that point is about
writeFile.I tested object counter with unit test and without using file guard for
writeFileI got panic about invalid count:Locking certainly fixes the bug, but why does it happen?
We can only
Unlinkonce with zero error, what is the problem?If object was deleted before
counter.Inc(), then size will be negative.The same situation could happen with
Inc()/Dec(), no? We just add a different constant here.Yes. Just before atomic was used and writecache has negative values handling.
@ -52,2 +62,4 @@func (w *linuxWriter) writeFile(p string, data []byte) error {if w.fileCounterEnabled {w.fileGuard.Lock(p)The whole point of
linuxWriterwas to avoid locking and use native linux facilities to ensure atomic write.This purpose is not defeated.
We have generic writer, which locks and does the same thing.
As far as I remember, the main idea of
linuxWriterwas to automatically delete temporary files in case of fail. Anyway locking doesn't affect too much:Unrelated to the commit.
Please retry comment: I don't see it now.
@ -0,0 +132,4 @@defer c.modeMtx.Unlock()var err errorif c.fsTree != nil {fsTree was here before, why there was no closing logic?
I don't know.
fstree.Closejust closes metrics, which are not defined for writecache. I decided to addClosecall anyway.@ -197,9 +153,6 @@ func (c *cache) flushFSTree(ctx context.Context, ignoreErrors bool) error {err = c.flushObject(ctx, &obj, e.ObjectData, StorageTypeFSTree)if err != nil {if ignoreErrors {Why?
Good question!
bbolt + fstreewritecache has different logic for error in case of flush for small and large objects:if err := c.flushObject(ctx, &obj, item.data, StorageTypeDB); err != nil {if err != nil {There also unit test that checks that flush returns an error in case of failed flush:
require.Error(t, wc.SetMode(mode.Degraded))So I changed flush implementation for FSTree to pass unit test.
Ok, it seems new implementation is correct:
flushcompletely leads to the same result.@ -172,0 +110,4 @@Address: objInfo.addr,})if err != nil {if !client.IsErrObjectNotFound(err) {This looks like a kludge, so this function is more like
flushIfAnObjectExistsWorker.Why do we delete in this thread and not in the one we list?
I decided to split
readworker that reads object addresses andflushworkers that read object data, save to blobstore and delete object. This is required to have more than one flush worker for fstree.Fixed.
I don't see how this is required, could you elaborate.
It doesn't matter in what worker we read file.
If there are 5 workers that read the same FSTree with current implementation of
fstree.Iterate, they could read the same file at the same time. So this comes to read overhead.@ -305,0 +238,4 @@address string}func (c *cache) flushAndDropBBoltDB(ctx context.Context) error {Could you put all
flushAndDrop*(i.e. something we would remove in future) in a separate file?Done
@ -321,3 +269,1 @@continue}return errreturn fmt.Errorf("unmarshal object from database: %w", err)Why was
if ignoreErrorsdropped?Why was
reportFlushErrordropped?This method is used now to flush and drop
small.boltdatabase file bywritecache.Init(). So these flags are not defined forInit. I think we should not to ignore errors as we want to drop the whole file. Also report flush error is useless, as shard will not be initialized in case of error.@ -0,0 +5,4 @@"sync")type flushLimiter struct {Please provide some comment about what this struct do, and what it is used for.
Done
@ -0,0 +18,4 @@}}func (l *flushLimiter) acquire(ctx context.Context, size uint64) error {Do we need to accept context here?
IMO it just makes it a lot harder to understand and use properly.
All stdlib
syncfacilities could be modelled as state machines, the context adds a whole new level of complexity because it can expire in any place in code, concurrently to the main logic.Signalling can be done with a variable: it is some Condition you could wait for.
I think we need to use
ctxhere to stop flushing as soon as possible. As far as I remember we already had bug with unable to stop service with timeout because of flushing objects from writecache.I agree we need to stop flushing by context.
My question was about
ctxbeing a part of theflushLimiterinterface vs being used in theflushitself.Ok, I moved this out from limiter.
Also moved limiter from writecache fields
@ -0,0 +19,4 @@}func (l *flushLimiter) acquire(ctx context.Context, size uint64) error {stopf := context.AfterFunc(ctx, func() {Will we leak a goroutine if we call this with
context.Background()?See https://pkg.go.dev/context#AfterFunc
If
ctxiscontext.Backgroud(), thenfunc()...will not be called.Am I missing something?
It seems if parent context (
context.Background()) was never cancelled,stopfcancells inherited context and, thus, goroutine stops@ -0,0 +49,4 @@if l.size >= size {l.size -= size} else {l.size = 0How about a panic here? We seem to hide some broken invariant by silently failing here.
Done
@ -0,0 +32,4 @@// it is allowed to overflow maxSize to allow flushing objects with size > maxSizefor l.count > 0 && l.size+size > l.maxSize {l.cond.Wait()This is the awesome approach to manage acquiring/releasing by goroutines 👍
6a5f0c9d50to78a554616b78a554616btod1c44de01c3b1795d22ftoc9286b2d69c9286b2d69tocfde039d2f@ -164,0 +69,4 @@}:return nilcase <-ctx.Done():c.flushLimiter.release(oi.DataSize)Added, missed this condition.
cfde039d2ftof1972fe26b5e038bdb19to95dfb724cc95dfb724ccto7ad0271a5b@ -0,0 +19,4 @@defer l.release(single)defer currSize.Add(-1)l.acquire(single)require.True(t, currSize.Add(1) <= 3)I believe some of the
tmethods are not thread safe (remember dataraces related tozaptest.Newlogger), could you ensurerequire.Truecan be safely called here?require.Truecallst.Fail(), that protected by mtx.@ -225,0 +278,4 @@continue}path := filepath.Join(curPath...)info, err := os.Stat(path)entries[i].Info()?fixed
@ -119,4 +114,3 @@} else {err = os.Remove(p)}unrelated
fixed
7ad0271a5btob33559754d