writecache: Fix race condition when reporting cache size metrics #1648
No reviewers
Labels
No labels
P0
P1
P2
P3
badger
frostfs-adm
frostfs-cli
frostfs-ir
frostfs-lens
frostfs-node
good first issue
triage
Infrastructure
blocked
bug
config
discussion
documentation
duplicate
enhancement
go
help wanted
internal
invalid
kludge
observability
perfomance
question
refactoring
wontfix
No milestone
No project
No assignees
3 participants
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference: TrueCloudLab/frostfs-node#1648
Loading…
Add table
Add a link
Reference in a new issue
No description provided.
Delete branch "a-savchuk/frostfs-node:fix-write-cache-object-count-metric"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
There is a race condition when multiple cache operation try to report the cache size metrics simultaneously. Consider the following example:
As a result, the observed cache size is 1 (i. e. one object remains in the cache), which is incorrect because the actual cache size is 0.
The behavior described above has been observed as shown in the screenshot below:
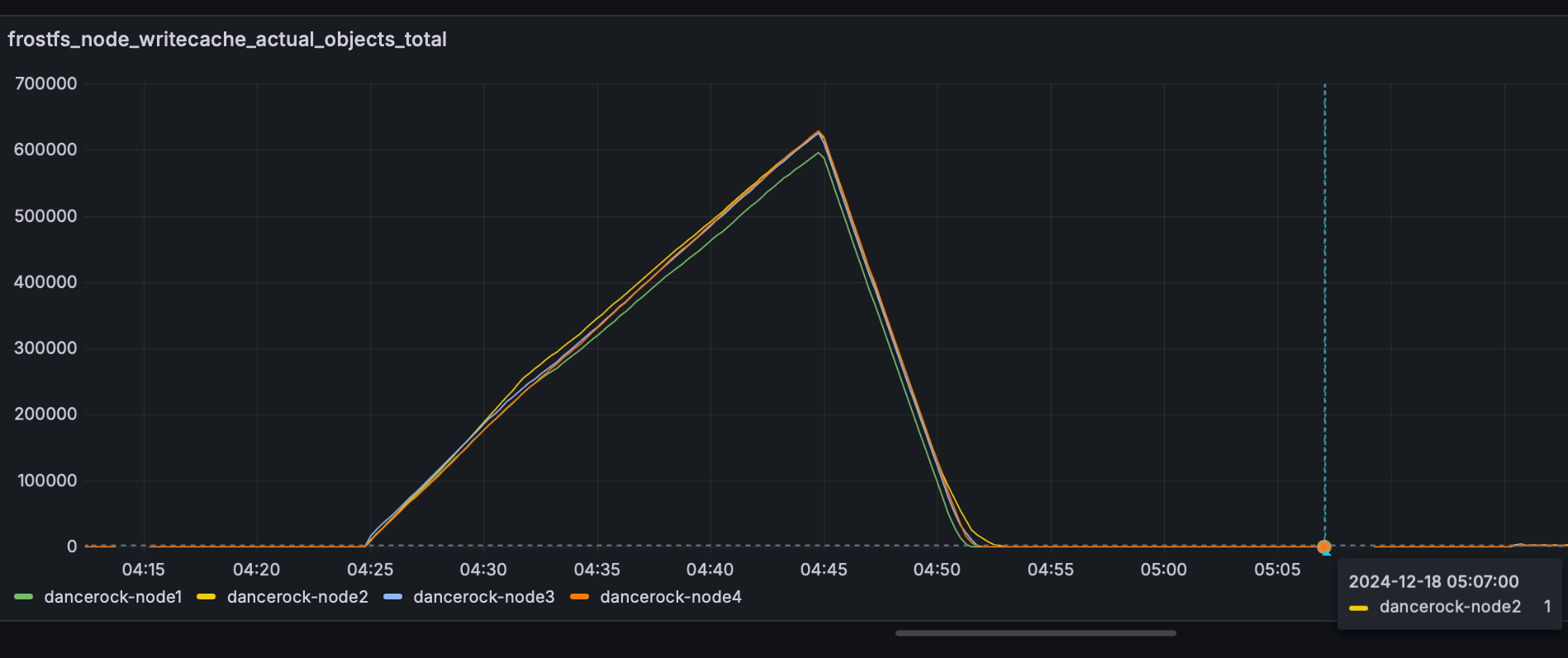
Also, this behavior is easily reproducible:

Also I added a debug log to track the reported cache object count values, here you can see the problem:
To fix this, let's report the metrics periodically in the flush loop.
f3c141de41tob28e45f5a4@ -99,2 +105,4 @@}func (c *cache) initSizeMetricsReporter() {c.sizeMetricsReporterQueue = make(chan struct{}, sizeMetricsReporterQueueSize)I suggest to use a buffered channel rather than an atomic/mutex. If you think different, feel free to argue. Also, let me know if you don't agree on the channel size. I think it can be calculated based on the cache parameters, for example like this
WIP: writecache: Fix race condition when reporting cache size metricsto writecache: Fix race condition when reporting cache size metricswritecache: Fix race condition when reporting cache size metricsto WIP: writecache: Fix race condition when reporting cache size metricsb28e45f5a4to840fc3a31b840fc3a31bto8f776b2f41WIP: writecache: Fix race condition when reporting cache size metricsto writecache: Fix race condition when reporting cache size metrics@ -52,4 +52,2 @@)c.metrics.Evict(StorageTypeFSTree)// counter changed by fstreec.estimateCacheSize()These
c.estimateCacheSize()calls do not need to be deleted.If there are many objects in the cache, the counters may not be updated for a very long time, because iteration over all objects can take tens of minutes.
Fixed
8f776b2f41to02f3a7f65c