Allow to seal writecache after flush #886
No reviewers
Labels
No labels
P0
P1
P2
P3
badger
frostfs-adm
frostfs-cli
frostfs-ir
frostfs-lens
frostfs-node
good first issue
triage
Infrastructure
blocked
bug
config
discussion
documentation
duplicate
enhancement
go
help wanted
internal
invalid
kludge
observability
perfomance
question
refactoring
wontfix
No milestone
No project
No assignees
5 participants
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference: TrueCloudLab/frostfs-node#886
Loading…
Add table
Reference in a new issue
No description provided.
Delete branch "dstepanov-yadro/frostfs-node:feat/flush_and_disable_writecache"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Added new flag
sealfor commandfrostfs-cli control shards flush-cache ... --sealthat changes writecache mode to read-only after flush.Fixed manual flush: now objects from DB will be deleted, previously only fstree object deleted.
Fixed manual flush 2: now it exclusive locks modeMtx, so manual flush doesn't conflict with background flush
PutandDeletemethods now return error immediately, if writecache is changing mode, closing or flushing objects with manual invokation.To check:
Start k6 to write data
Grafana shows that writecache stores objects
Run
frostfs-cli control shards flush-cache --id <shard_id> --endpoint ... --wallet ... --sealGrafana shows that writecache has stopped to store objects, all objects were flushed, mode was changed:
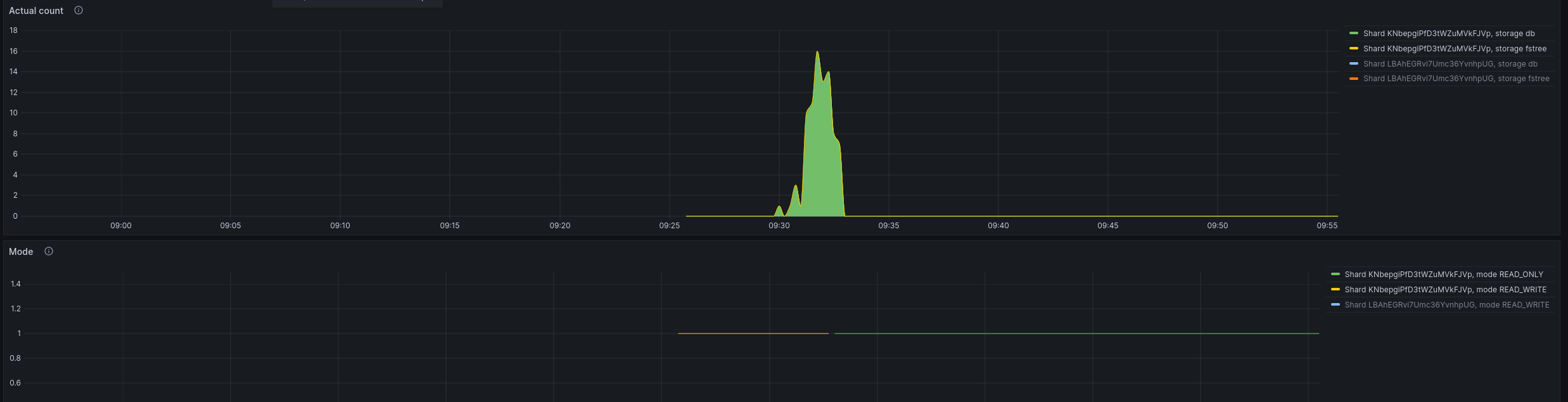
UPD:
Also added
frostfs-cli control shards writecache sealthat does almost the same asfrostfs-cli control shards flush-cache --seal, but moves writecache to degraded read only mode.Output example:
Relates #569
33790b2d94to58702a57e7@ -239,3 +239,3 @@// Write-cache must be in readonly mode to ensure correctness of an operation and// to prevent interference with background flush workers.func (c *cache) Flush(ctx context.Context, ignoreErrors bool) error {func (c *cache) Flush(ctx context.Context, ignoreErrors, _ bool) error {Decided to drop badger implementation, so no changed here.
Don't understand -- if we dropped badger and rebased, why this change?
Oh, I see now.
@ -34,3 +35,3 @@}()c.modeMtx.RLock()if !c.modeMtx.TryRLock() {Writecache is closing, changing mode or flushing. So no need to wait, this step will be skipped.
@ -136,13 +139,11 @@ func (c *cache) flushSmallObjects(ctx context.Context) {}}c.modeMtx.RUnlock()refactoring
@ -293,2 +301,3 @@return c.db.View(func(tx *bbolt.Tx) error {for {batch, err := c.readNextDBBatch(ignoreErrors)Batching added to not to store all objects in single slice for delete.
@ -44,3 +44,3 @@}()c.modeMtx.RLock()if !c.modeMtx.TryRLock() {Writecache is closing, changing mode or flushing. So no need to wait, this step will be skipped.
It seems like a separate change in behavior, it deserves a separate commit.
Done
@ -69,3 +69,3 @@}func (c *cache) deleteFromDB(key string) {func (c *cache) deleteFromDB(key string, batched bool) {When flush started by external command, there is no need for batching, because deletion processes in single goroutine.
Allow to seal writecache after flushto WIP: Allow to seal writecache after flush58702a57e7to0605da30de@ -68,4 +68,2 @@require.Error(t, wc.SetMode(mode.Degraded))// First move to read-only mode to close background workers.require.NoError(t, wc.SetMode(mode.ReadOnly))It was used to stop background workers. Now background workers disabled with writecache option. Also setting read-only mode makes it impossible to delete objects from db.
WIP: Allow to seal writecache after flushto Allow to seal writecache after flush0605da30detof49fefe3ad@ -33,3 +34,3 @@}()c.modeMtx.RLock()if !c.modeMtx.TryRLock() {If writecache is doing something, why don't we just hang here? Anyway, if it is not related to sealing, how about doing it in a separate commit or before your changes -- it deserves a separate description.
Writecache is not mandatory, but it can take a lot of time to flush for example. Also if modeMtx is locked, then highly likely writecache will be unavailable for write. So put or delete can be processed with blobstor directly.
@ -135,13 +138,11 @@ func (c *cache) flushSmallObjects(ctx context.Context) {}}c.modeMtx.RUnlock()Pure refactoring, please, make it a separate commit.
Done.
@ -281,3 +281,2 @@c.modeMtx.RLock()defer c.modeMtx.RUnlock()c.modeMtx.Lock() // exclusive lock to not to conflict with background flushWhat do you mean by "conflict with background flush"?
Both flushes do the same, here we just need to return after everything is flushed.
Background flush acquires RLock, so only one flush will be in process: background or manual
@ -77,1 +72,3 @@})var err errorif batched {err = c.db.Batch(func(tx *bbolt.Tx) error {Again, an optimization, please, separate commit.
No, it isn't an optimization: for manual flush we don't need batch.
Why is manual flush single-threaded then?
To reduce complexity. No need to do manual flush as fast as possible.
On the contrary 8 hours vs 1 hour can make a difference -- this is all done by a human.
Looks like that these values taken not from real life: flush works pretty fast now.
@ -284,2 +283,3 @@defer c.modeMtx.Unlock()return c.flush(ctx, ignoreErrors)if err := c.flush(ctx, ignoreErrors); err != nil {There are 2 cases to consider:
What is the behaviour in these situations? It looks like we should fail in both:
And we will fail:
func (s *Shard) FlushWriteCache(ctx context.Context, p FlushWriteCachePrm) error {f49fefe3adtoa1c438acd4a1c438acd4to20e9670f9a98fd3bb184to5a9f1718045a9f171804to11de6264e0@ -16,0 +15,4 @@Short: "Flush objects from the write-cache to the main storage",Long: "Flush objects from the write-cache to the main storage",Run: flushCache,Deprecated: "Flushing objects from writecache to the main storage performs by writecache automatically. To flush and seal writecache use `frostfs-cli control shards writecache seal`.",s/performs/is performed by/
fixed
@ -0,0 +53,4 @@cmd.Printf("Shard %s: OK\n", base58.Encode(res.GetShard_ID()))} else {failed++cmd.Printf("Shard %s: failed with error \"%s\"\n", base58.Encode(res.GetShard_ID()), res.GetError())\"%s\"->%q?fixed
@ -0,0 +29,4 @@for _, r := range res.ShardResults {if r.Success {resp.Body.Results = append(resp.GetBody().GetResults(), &control.SealWriteCacheResponse_Body_Status{Shard_ID: r.ShardID.Bytes(),Doesn't
*r.ShardIDwork? We already have similar code in other parts.fixed
11de6264e0to5afad725d35afad725d3to581887148a