Add off-cpu profiler #1462
No reviewers
Labels
No labels
P0
P1
P2
P3
badger
frostfs-adm
frostfs-cli
frostfs-ir
frostfs-lens
frostfs-node
good first issue
triage
Infrastructure
blocked
bug
config
discussion
documentation
duplicate
enhancement
go
help wanted
internal
invalid
kludge
observability
perfomance
question
refactoring
wontfix
No milestone
No project
No assignees
4 participants
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference: TrueCloudLab/frostfs-node#1462
Loading…
Add table
Reference in a new issue
No description provided.
Delete branch "dstepanov-yadro/frostfs-node:feat/off_cpu_profiler"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Default golang profiler is on-cpu profiler, so it shows only on CPU time. But for performance testing it is required sometimes to see distribution for all payloads: cpu and i/o.
Comparison with master on 5 min write tests for 8KB, 128KB, 1MB:
master:
branch:
Examples: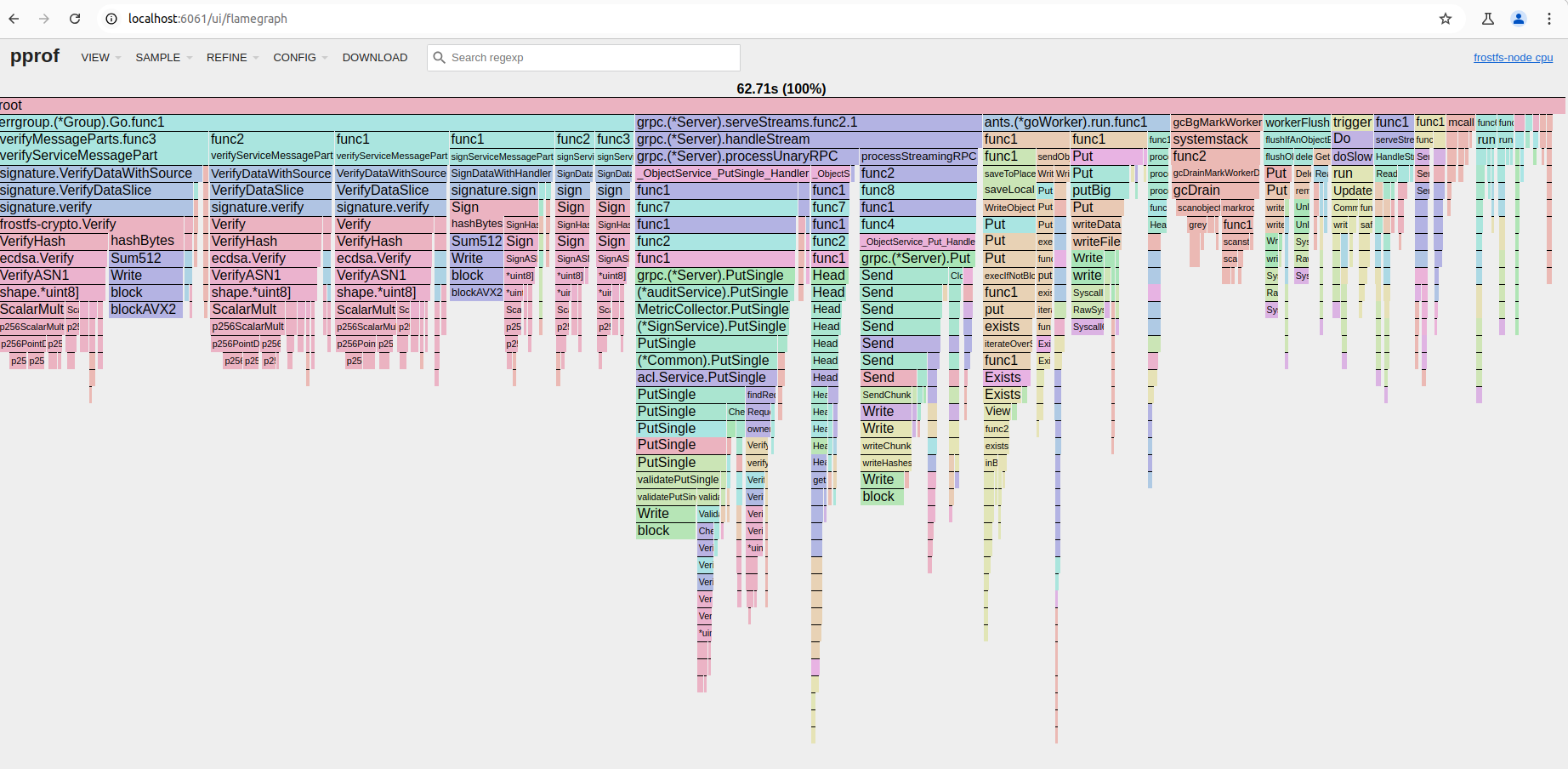
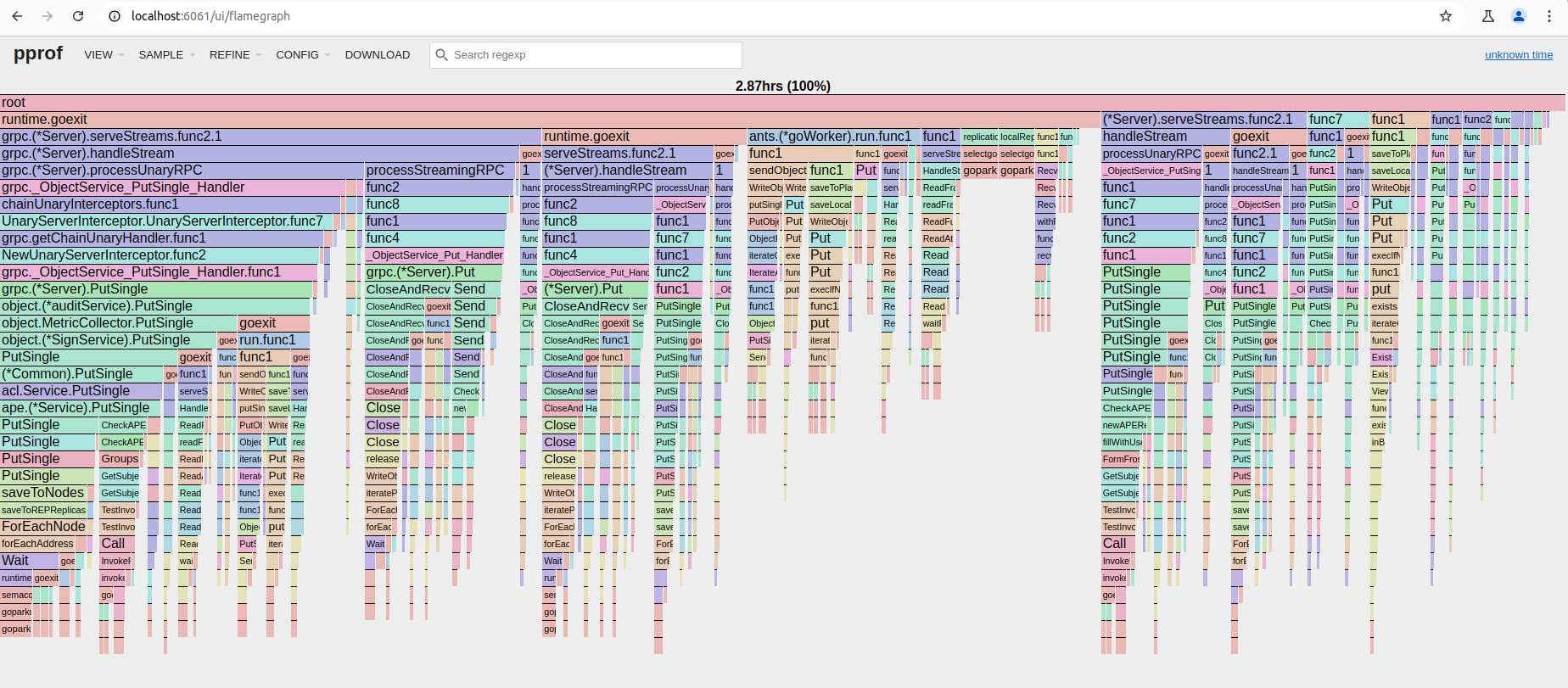
default profiler:
off-cpu profiler:
The main tradeoff is performance: off-cpu profiler has greater impact on app performance
Tested on hardware (10 min, 600 VUS, 8kb write):
without profile collect:
with collecting profile every 10s for 3s:
Perhaps the profile collecting effect shows intesf at a higher load.
5 min, 1000VUS, write 8KB
without profile collecting - 55MB/s
with profile collecting for 3 second every 10 seconds - 49MB/s
33318bf58cto3bf5862d09Seems like our case. 2 questions:
fgprof.Handler()collects goroutines stacks only when profile collect is in progress3bf5862d09tod19ab43500WIP: Add off-cpu profilerto Add off-cpu profiler